
GPT-4 viene siendo el modelo líder con su habilidad impresionante para manejar texto. Pero, ¿qué pasaría si te dijéramos que su poder ha sido utilizado para entrenar un modelo muy avanzado que integra tanto imágenes como texto? Eso es exactamente como surgió LLaVA.
El Nacimiento de LLaVA, Una Unión de Texto e Imagen
Liu et al. introdujeron LLaVA, un modelo de inteligencia artificial que no solo comprende y sigue prompts basados en el lenguaje, sino que también entiende imágenes, creando un entendimiento de los datos visuales y lingüísticos simultáneamente. Pero, ¿cómo se creó LLaVA exactamente?
Usando GPT-4 para Crear un Set de Datos Instructivo
GPT-4, con su dominio sobre el lenguaje, ha sido utilizado para generar datos que entrenan a LLaVA, generando un set de datos que mezcla las instrucciones lingüísticas con imágenes correspondientes. Esto se logró dando a GPT-4 descripciones de imágenes (sin mostrarle las imágenes) y permitiéndole producir diversos tipos de salidas, desde preguntas y respuestas hasta descripciones detalladas, creando así un rico set de datos para entrenar a LLaVA.
La Creación de LLaVA a Través de la Sintonización de Instrucciones Visuales
La técnica llamada “visual instruction tuning” utiliza las preguntas generadas por GPT-4, junto con las imágenes reales, para entrenar a LLaVA para entender y responder preguntas sobre la imagen – todo esto sin depender de las descripciones de texto. LLaVA entrelaza la comprensión de la imagen y el texto para proporcionar respuestas relevantes y precisas sobre el contenido visual.
Una Fusión de Poderes: CLIP, LLaMA, y GPT-4
LLaVA es esencialmente una combinación de tecnologías de IA. Utiliza LLaMA, otro modelo de lenguaje grande, como su base para el entendimiento lingüístico, mientras que CLIP, un modelo previamente entrenado, se utiliza para traducir las imágenes en un formato comprensible para LLaMA. La confluencia de estos modelos, con la ayuda de GPT-4 para el entrenamiento inicial, culmina en la creación de LLaVA, un modelo capaz de comprender y responder preguntas acerca de imágenes y texto con mucha eficacia.
LLaVA en Acción y el Futuro de la IA Multimodal
Los investigadores han hecho que su trabajo, incluyendo LLaVA, sea de código abierto y han compartido una demostración on-line para que el público pueda explorar sus capacidades. Es un testimonio de cómo la combinación de múltiples modelos y técnicas de IA puede dar lugar a un modelo multimodal poderoso y altamente aplicable en diversos campos. Esto es solo el comienzo: la utilización de GPT-4 y otros modelos poderosos para crear IAs más avanzadas es una frontera que apenas estamos comenzando a explorar.
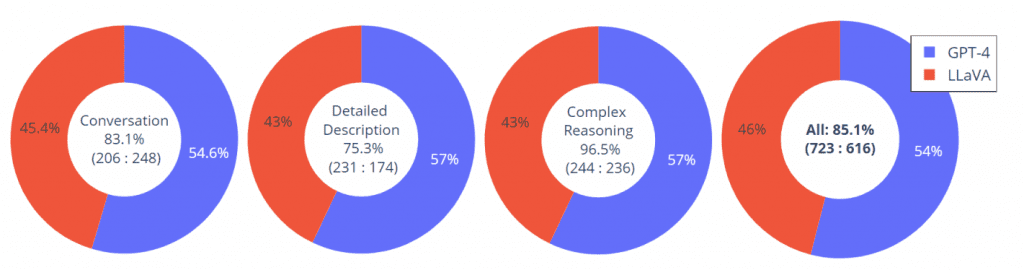
Resultados que Hablan: Desempeño de LLaVA
LLaVA muestra un potencial prometedor en el chat multimodal, que alcanza un 85.1% de puntuación relativa a GPT-4. En la imagen a continuación, se puede ver su desempeño en conversación, descripciones detalladas, razonamiento complejo y desempeño integral.
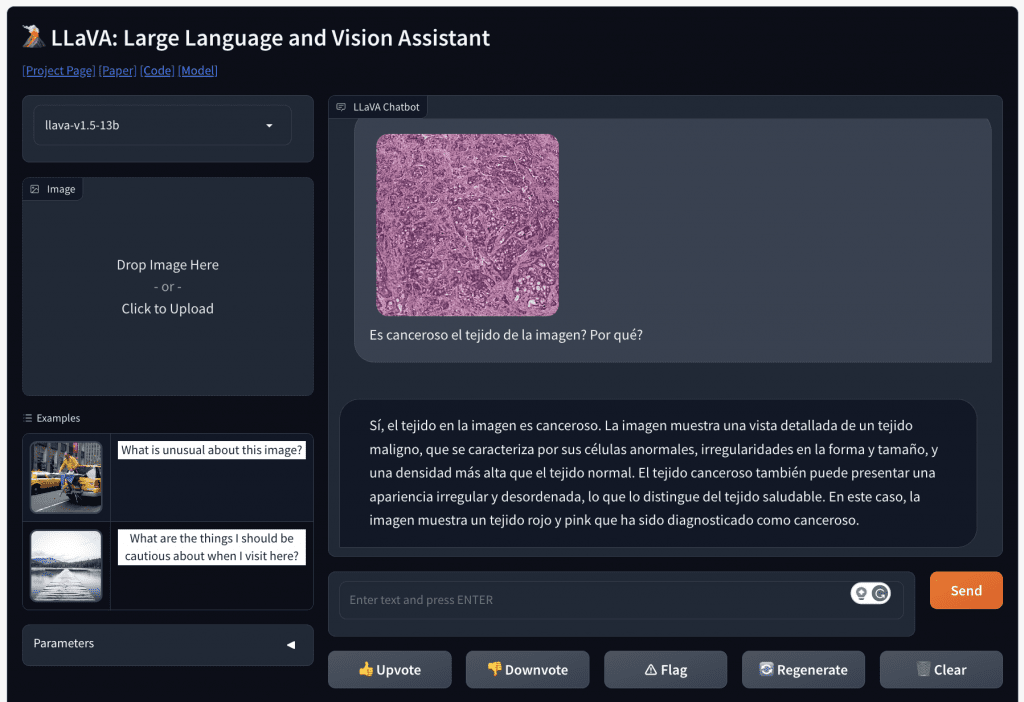
Probando LLaVA
Podés acceder a la demo de LLaVA haciendo click acá. Te mostramos un ejemplo de cómo estuvimos probándolo nosotros mismos:
Conclusiones
Esta es una pista de lo que el futuro de la IA tiene reservado: modelos colaborando para crear tecnologías aún más avanzadas. Seguinos en IngenieriaDePrompts.AI para conocer más de estas novedades.
PD: La imagen fue creada usando MidJourney. El prompt que se le dio fue “Computer Vision AI”. Qué te pareció?

